

























")






Hashing in data structures is one of the major concept of data structures and is mostly used to search.
But why hashing when linear or binary search is there already?
Time is the answer
Time complexity for linear search is O(n).
Time complexity for binary search is O(logn) which is much better than the linear search but binary search can be applied only on the sorted array.
But time complexity for searching a key in an array using hashing is O(1) . Yes, constant time.
So hashing in data structures is an important concept to study.
Simple example
Consider the following array A. Find the largest element. Here, 18, So we will create a hash array/table of size 1+largest element, that is 19 and assign all the elements of it as 0.


Iterate through our main array A and assign each element’s value to the hash array H such that the value and the index at which the value is assigned is equal to that element’s value. Like shown below.

Now from this hashing array we can determine if the element is present or not. For example, searching for key 10, we’ll look for 10 at index 10 of hash array H. So searching is of constant time unlike linear and binary search.
Drawback
If a much larger element is present, for example 100, then we will have to create a hash array of size 101, that will take a lot of space even for implementing this hash search on a small size array.
Mappings
- One-one
- One-many
- Many-one
- Many-many
One-many and Many-one relations are also known as functions.
One-one approach
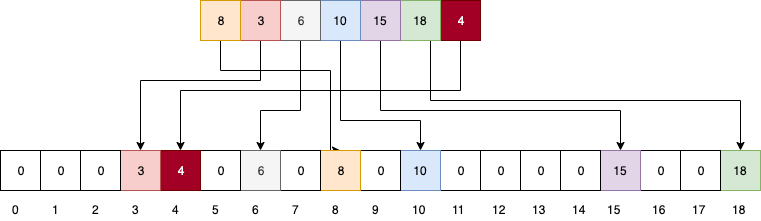
Here each element of main array is linked to only one element of hash array.
H(x) = x;
Many-one approach
Here we will use function H(x) = x%10;
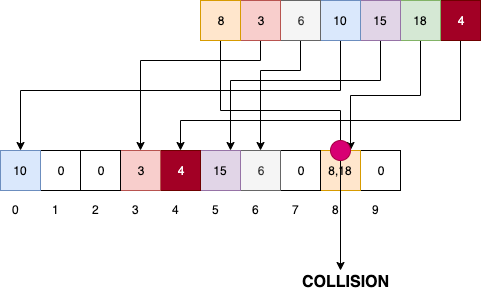
Here only limited size hash array is required as we are only assigning remainder(x%10) to the hash array.
So space problem is solved with Many-one.But a new problem arrises that is, COLLISION , can be seen at index 8 of the hash array.
To solve this various approaches are available
Open hashing
- Chaining
Closed hashing
- Open addressing
- Linear probing
- Quadratic probing
- Double probing
Additional – Sorting, Basics of Array, Linked List
Smart Parking System IOT Project
How to download turbo c+ on macbook air/macbook pro/mac os?
How to add splash screen or starting logo screen in android studio?
Learn everything about binary search tree in python







")





{kind=link}
[…] What is hashing in data structures? […]